Best Horror Games to Play This Halloween Season
It's the spooky time of the year, so here are some of the best horror games you can play to give yourself a good scare.
The Tongyi Qianwen team announced that three months after the release of Qwen2, the latest member of the Qwen family, the Qwen2.5 series of language models, is officially open source. This marks what may be one of the largest open source releases in history, including the general language model Qwen2.5, as well as the Qwen2.5-Coder and Qwen2.5-Math models specifically targeted at the programming and mathematics fields.
The Qwen2.5 series models are pre-trained on the latest large-scale data set, which contains up to 18T tokens. Compared with Qwen2, the new model has significantly improved in knowledge acquisition, programming ability and mathematical ability. The model supports long text processing, can generate content up to 8K tokens, and maintains support for more than 29 languages.

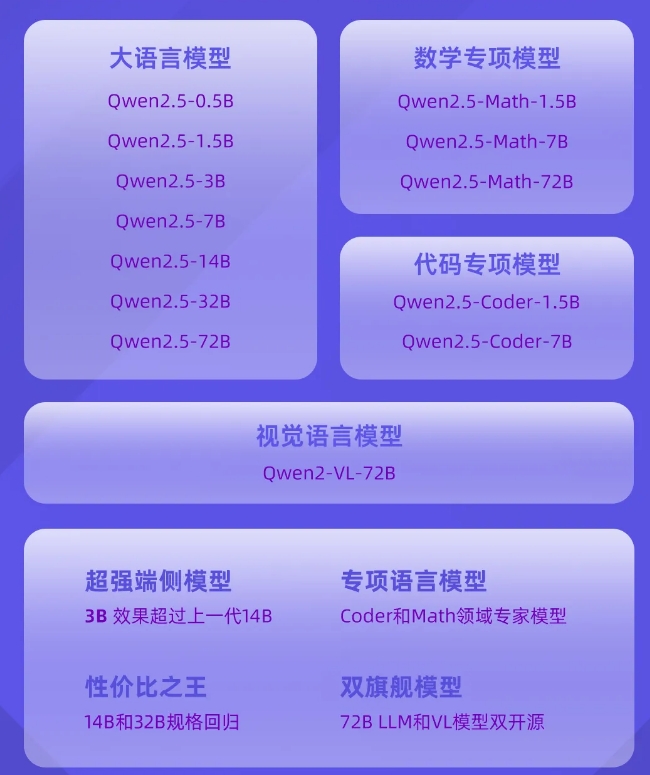
The open source Qwen2.5 series models not only adopt the Apache2.0 license, but also provide a variety of versions of different sizes to adapt to different application needs. In addition, the Tongyi Qianwen team also open sourced the Qwen2-VL-72B model with performance comparable to GPT-4.
The new model achieves significant improvements in instruction execution, long text generation, structured data understanding, and generating structured output. Especially in the fields of programming and mathematics, the Qwen2.5-Coder and Qwen2.5-Math models were trained on professional data sets, demonstrating stronger capabilities in professional fields.
Qwen2.5 series model experience:
Qwen2.5 collection: https://modelscope.cn/studios/qwen/Qwen2.5