Beste Horrorspiele, um diese Halloween -Saison zu spielen
Es ist die gruselige Jahreszeit des Jahres. Hier sind einige der besten Horrorspiele, die Sie spielen können, um sich einen guten Angst zu machen.
Das Team von Tongyi Qianwen gab bekannt, dass drei Monate nach der Veröffentlichung von Qwen2 das neueste Mitglied der Qwen-Familie, die Qwen2.5-Sprachmodellserie, offiziell Open Source ist. Dies ist möglicherweise eine der größten Open-Source-Veröffentlichungen in der Geschichte, einschließlich des allgemeinen Sprachmodells Qwen2.5 sowie der Modelle Qwen2.5-Coder und Qwen2.5-Math, die speziell auf die Bereiche Programmierung und Mathematik ausgerichtet sind.
Die Modelle der Qwen2.5-Serie werden anhand des neuesten umfangreichen Datensatzes vorab trainiert, der bis zu 18T-Token enthält. Im Vergleich zu Qwen2 hat sich das neue Modell hinsichtlich Wissenserwerb, Programmierfähigkeit und mathematischen Fähigkeiten erheblich verbessert. Das Modell unterstützt die Langtextverarbeitung, kann Inhalte mit bis zu 8K-Tokens generieren und unterstützt mehr als 29 Sprachen.

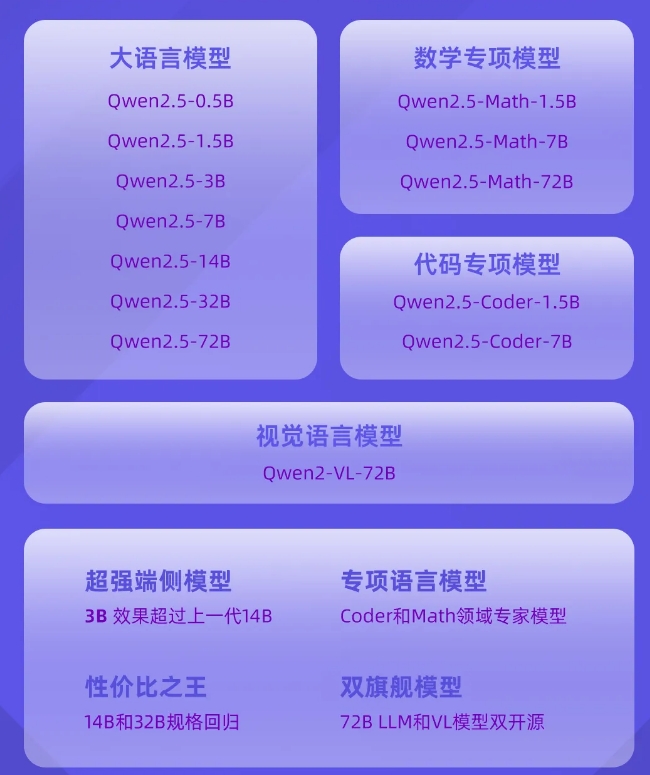
Die Open-Source-Modelle der Qwen2.5-Serie übernehmen nicht nur die Apache2.0-Lizenz, sondern bieten auch eine Vielzahl von Versionen unterschiedlicher Größe, um sich an unterschiedliche Anwendungsanforderungen anzupassen. Darüber hinaus hat das Team von Tongyi Qianwen auch das Modell Qwen2-VL-72B mit einer mit GPT-4 vergleichbaren Leistung als Open Source bereitgestellt.
Das neue Modell erzielt erhebliche Verbesserungen bei der Befehlsausführung, der Langtextgenerierung, dem Verständnis strukturierter Daten und der Generierung strukturierter Ausgaben. Insbesondere in den Bereichen Programmierung und Mathematik wurden die Modelle Qwen2.5-Coder und Qwen2.5-Math anhand professioneller Datensätze trainiert und zeigten stärkere Fähigkeiten in beruflichen Bereichen.
Modellerfahrung der Qwen2.5-Serie:
Qwen2.5-Sammlung: https://modelscope.cn/studios/qwen/Qwen2.5