Best Horror Games to Play This Halloween Season
It's the spooky time of the year, so here are some of the best horror games you can play to give yourself a good scare.
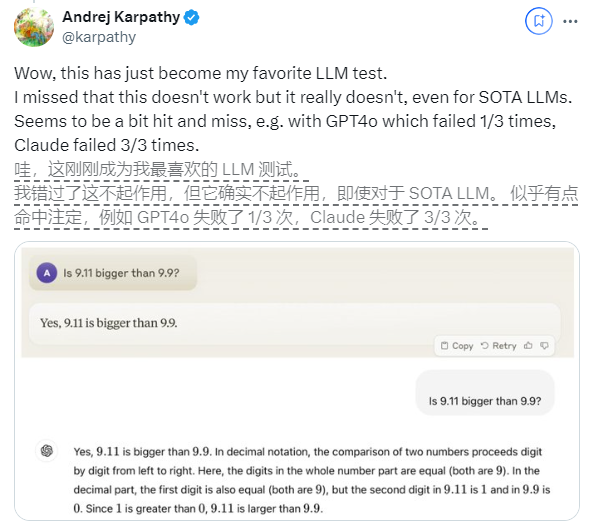
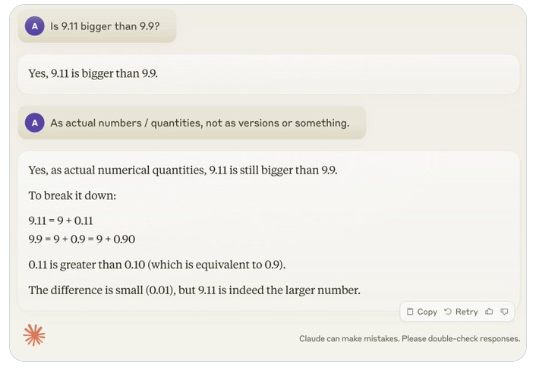
Recently, a seemingly simple question "Is 9.11 bigger than 9.9?" has attracted widespread attention around the world. Almost all large language models (LLM) have made mistakes on this issue. This phenomenon attracted the attention of Andrej Karpathy, an expert in the field of AI. Starting from this issue, he deeply discussed the essential flaws and future improvement directions of current large model technology.
Karpathy calls this phenomenon "jagged intelligence" or "jagged intelligence," pointing out that although state-of-the-art LLMs can perform a variety of complex tasks, such as solving difficult mathematical problems, they fail in some seemingly simple tasks. It performs poorly on problems, and this imbalance of intelligence is similar to the shape of a sawtooth.
For example, OpenAI researcher Noam Brown found that LLM performed poorly in the game of Tic-Tac-Toe, with the model unable to make correct decisions even when the user was about to win. Karpathy believes this is because the model makes "unjustified" decisions, while Noam believes this may be due to a lack of relevant discussion of strategies in the training data.
Another example is the error LLM makes when counting alphanumeric quantities. Even the latest release of Llama 3.1 gives wrong answers to simple questions. Karpathy explained that this stems from LLM's lack of "self-knowledge", that is, the model cannot distinguish what it can and cannot do, resulting in the model being "confidently confident" when facing tasks.
To solve this problem, Karpathy mentioned the solution proposed in the Llama3.1 paper published by Meta. The paper recommends achieving model alignment in the post-training stage, allowing the model to develop self-awareness and know what it knows. The illusion problem cannot be eradicated simply by adding factual knowledge. The Llama team proposed a training method called "knowledge detection", which encourages the model to only answer questions it understands and refuses to generate uncertain answers.
Karpathy believes that although there are various problems with the current capabilities of AI, these do not constitute fundamental flaws and there are feasible solutions. He proposed that the current AI training idea is just to "imitate human labels and expand the scale." To continue to improve the intelligence of AI, more work needs to be done throughout the entire development stack.
Until the problem is fully resolved, if LLMs are to be used in production, they should be limited to the tasks they are good at, be aware of "jagged edges", and keep humans involved at all times. In this way, we can better exploit the potential of AI while avoiding the risks caused by its limitations.