Beste Horrorspiele, um diese Halloween -Saison zu spielen
Es ist die gruselige Jahreszeit des Jahres. Hier sind einige der besten Horrorspiele, die Sie spielen können, um sich einen guten Angst zu machen.
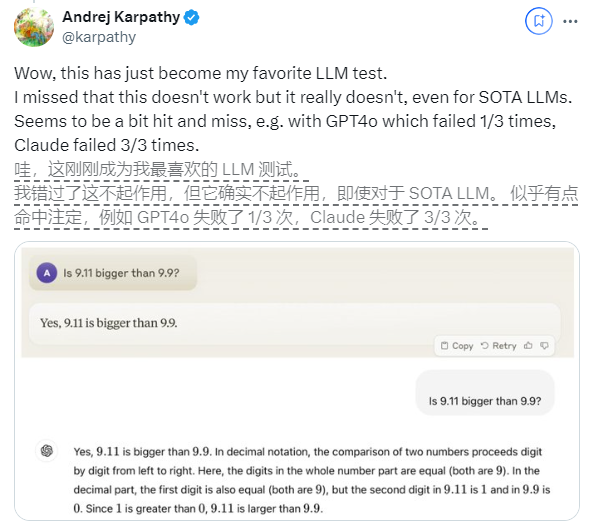
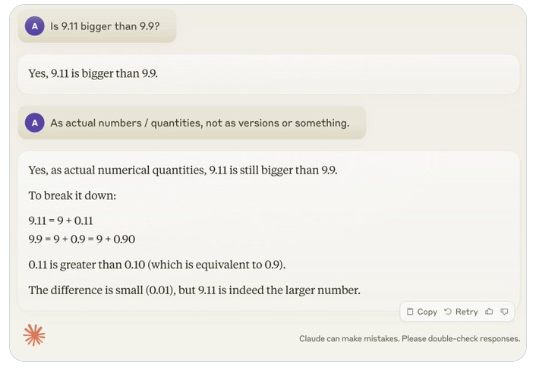
In letzter Zeit hat die scheinbar einfache Frage „Ist 9.11 größer als 9.9?“ weltweit große Aufmerksamkeit erregt. Fast alle großen Sprachmodelle (LLM) haben in dieser Frage Fehler gemacht. Dieses Phänomen erregte die Aufmerksamkeit von Andrej Karpathy, einem Experten auf dem Gebiet der KI. Ausgehend von dieser Ausgabe diskutierte er eingehend die wesentlichen Mängel und zukünftige Verbesserungsrichtungen der aktuellen Großmodelltechnologie.
Karpathy nennt dieses Phänomen „gezackte Intelligenz“ oder „gezackte Intelligenz“ und weist darauf hin, dass hochmoderne LLMs zwar eine Vielzahl komplexer Aufgaben erfüllen können, beispielsweise das Lösen schwieriger mathematischer Probleme, bei einigen scheinbar einfachen Aufgaben jedoch versagen schneidet bei Problemen schlecht ab, und dieses Ungleichgewicht der Intelligenz ähnelt der Form eines Sägezahns.
Der OpenAI-Forscher Noam Brown stellte beispielsweise fest, dass LLM im Spiel Tic-Tac-Toe schlecht abschneidet, da das Modell selbst dann nicht in der Lage ist, richtige Entscheidungen zu treffen, wenn der Benutzer kurz vor dem Sieg steht. Karpathy glaubt, dass dies daran liegt, dass das Modell „ungerechtfertigte“ Entscheidungen trifft, während Noam glaubt, dass dies möglicherweise an einer fehlenden relevanten Diskussion der Strategien in den Trainingsdaten liegt.
Ein weiteres Beispiel ist der Fehler, den LLM beim Zählen alphanumerischer Mengen macht. Selbst die neueste Version von Llama 3.1 gibt falsche Antworten auf einfache Fragen. Karpathy erklärte, dass dies auf die mangelnde „Selbsterkenntnis“ von LLM zurückzuführen sei, d.
Um dieses Problem zu lösen, erwähnte Karpathy die im von Meta veröffentlichten Llama3.1-Artikel vorgeschlagene Lösung. Das Papier empfiehlt, die Modellausrichtung in der Phase nach dem Training zu erreichen, damit das Modell Selbstbewusstsein entwickeln und wissen kann, was es weiß. Das Illusionsproblem kann nicht einfach durch Hinzufügen von Faktenwissen beseitigt werden. Das Llama-Team schlug eine Trainingsmethode namens „Wissenserkennung“ vor, die das Modell dazu ermutigt, nur Fragen zu beantworten, die es versteht, und sich weigert, unsichere Antworten zu generieren.
Karpathy ist davon überzeugt, dass es zwar verschiedene Probleme mit den aktuellen Fähigkeiten der KI gibt, diese jedoch keine grundlegenden Mängel darstellen und es praktikable Lösungen gibt. Er schlug vor, dass die aktuelle KI-Trainingsidee lediglich darin besteht, „menschliche Etiketten zu imitieren und den Maßstab zu erweitern“. Um die Intelligenz der KI weiter zu verbessern, muss im gesamten Entwicklungsstapel mehr Arbeit geleistet werden.
Bis das Problem vollständig gelöst ist, sollten LLMs, wenn sie in der Produktion eingesetzt werden sollen, auf die Aufgaben beschränkt werden, in denen sie gut sind, sich der „gezackten Kanten“ bewusst sein und den Menschen jederzeit einbeziehen. Auf diese Weise können wir das Potenzial der KI besser ausschöpfen und gleichzeitig die Risiken vermeiden, die sich aus ihren Einschränkungen ergeben.