このハロウィーンシーズンをプレイする最高のホラーゲーム
それは今年の不気味な時期ですので、ここにあなたが自分自身に良い恐怖を与えるためにプレイできる最高のホラーゲームのいくつかがあります。
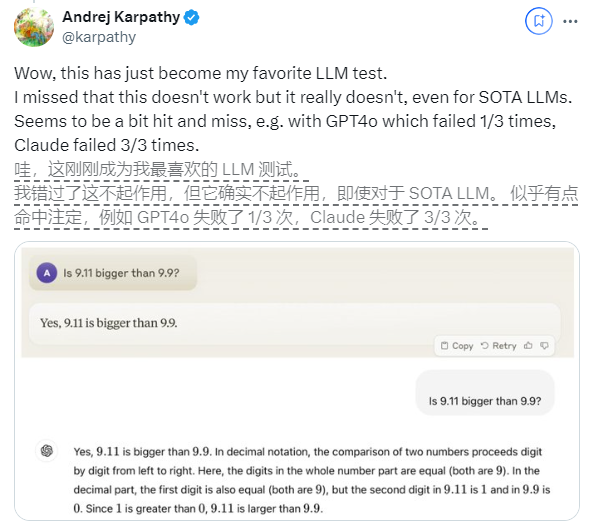
最近、「9.11 は 9.9 より大きいのか?」という一見単純な疑問が世界中で広く注目を集めていますが、この問題に関してはほとんどすべての大規模言語モデル (LLM) が間違いを犯しています。この現象は、AI 分野の専門家である Andrej Karpathy 氏の注目を集め、この問題を皮切りに、現在の大型モデル技術の本質的な欠陥と今後の改善の方向性について深く議論しました。
Karpathy 氏はこの現象を「ギザギザの知能」または「ギザギザの知能」と呼び、最先端の LLM は難しい数学的問題を解くなど、さまざまな複雑なタスクを実行できるものの、一見単純なタスクの一部では失敗することを指摘しています。問題に対するパフォーマンスが悪く、この知性の不均衡はノコギリの歯の形に似ています。
たとえば、OpenAI 研究者の Noam Brown 氏は、LLM のパフォーマンスが三目並べのゲームで低く、ユーザーが勝ちそうになっている場合でもモデルが正しい判断を下すことができないことを発見しました。 Karpathy 氏は、これはモデルが「不当な」決定を下すためであると考えていますが、Noam 氏は、これはトレーニング データ内の戦略に関する適切な議論が欠如していることが原因である可能性があると考えています。
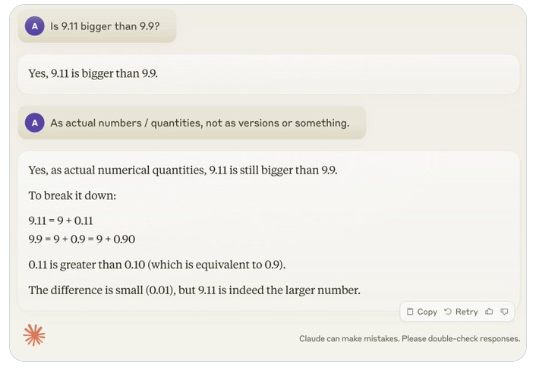
もう 1 つの例は、英数字の数量を数えるときに LLM が犯すエラーです。 Llama 3.1 の最新リリースでさえ、単純な質問に対して間違った答えを示しています。 Karpathy 氏は、これは LLM の「自己知識」の欠如に起因すると説明しました。つまり、モデルが自分にできることとできないことを区別できず、その結果、タスクに直面するときにモデルが「自信満々」になってしまうのです。
この問題を解決するために、Karpathy 氏は、Meta が発行した Llama3.1 論文で提案されている解決策について言及しました。この論文では、トレーニング後の段階でモデルの整合性を確立し、モデルが自己認識を高め、モデルが何を知っているかを知ることができるようにすることを推奨しています。事実の知識を追加するだけでは錯覚の問題を根絶することはできません。 Llama チームは、「知識検出」と呼ばれるトレーニング方法を提案しました。これは、モデルが理解している質問にのみ回答するように促し、不確実な回答を生成することを拒否します。
Karpathy 氏は、AI の現在の機能にはさまざまな問題があるものの、これらは根本的な欠陥ではなく、実行可能な解決策があると考えています。同氏は、現在の AI トレーニングのアイデアは「人間のラベルを模倣して規模を拡大する」だけであると提案し、AI の知能を向上し続けるには、開発スタック全体でさらに多くの作業を行う必要があると述べました。
問題が完全に解決されるまで、LLM を運用環境で使用する場合は、LLM が得意なタスクに限定し、「ギザギザのエッジ」に注意し、常に人間が関与し続ける必要があります。このようにして、AI の限界によって引き起こされるリスクを回避しながら、AI の可能性をより適切に活用することができます。