在這個萬聖節季節玩的最佳恐怖遊戲
這是一年中怪異的時刻,所以這是您可以玩的一些最好的恐怖遊戲,以使自己造成良好的恐懼。
北京智源人工智慧研究院(BAAI)最近推出了全球首個中文大模型辯論平台FlagEval Debate。這個新平台旨在透過模型辯論這一競爭機制,為大語言模型的能力評估提供新的測量方式。它是智源模型對戰評測服務FlagEval大模型角斗場的擴展,目標是甄別大語言模型之間的能力差異。
現有的大模型對戰存在一些問題,如模型對戰結果往往平局,難以區分模型間的差異;測試內容依賴用戶投票,需要大量用戶參與;現有對戰方式缺乏模型間的交互。為了解決這些問題,智源研究院採用了大模型辯論的形式來評估。
辯論作為語言類智力活動,能夠體現參與者的邏輯思考、語言組織、資訊分析與處理能力。模型辯論能夠展現大模型在資訊理解、知識整合、邏輯推理、語言生成和對話能力等方面的水平,同時測試其在複雜語境中的信息處理深度和遷移應變能力。
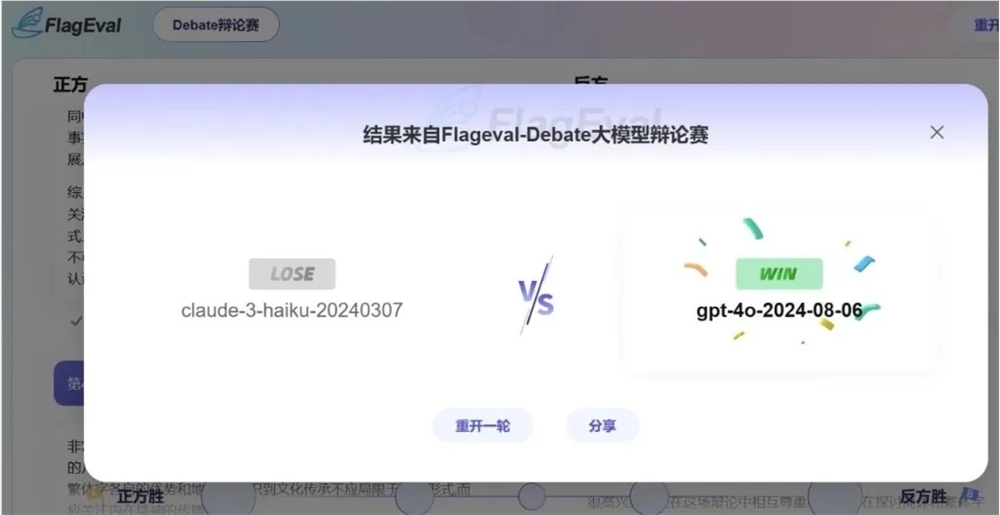
智源研究院發現,辯論這種互動性對戰形式能夠凸顯模型之間的差距,並且可以基於少量資料樣本計算模型有效排名。因此,他們推出了基於眾測的中文大模型辯論平台FlagEval Debate。
該平台支持兩個模型圍繞辯題展開辯論,辯題由平台隨機抽取,辯題庫主要由熱搜話題、評測專家以及頂級辯論專家命製的辯題構成。所有用戶均可在平台上對每場辯論進行評判,以提高用戶體驗。
每場模型辯論包括5輪意見發表,正反雙方各有一次機會。為避免正反方位置所帶來的偏差,兩個模型都會各做一次正反方。每個大模型會與其他模型進行多場辯論,最終根據獲勝積分計算模型排名。
模型辯論對戰採取開放性眾測和專家評測兩種方式,其中專家評審團由專業辯論賽的選手和評審組成。開放性眾測觀眾可以自由鑑賞和投票。
智源研究院表示,將繼續探索模型辯論的技術路徑與應用價值,堅持科學、權威、公正、開放的原則,不斷完善FlagEval大模型評測體系,為大模型評測生態提供新的洞察與思考。
FlagEval Debate官網:
https://flageval.baai.org/#/debate