أفضل ألعاب الرعب للعب موسم الهالوين هذا
إنه الوقت المخيف من العام ، لذا إليك بعضًا من أفضل ألعاب الرعب التي يمكنك لعبها لمنح نفسك تخويفًا جيدًا.
أطلق معهد بكين تشي يوان لأبحاث الذكاء الاصطناعي (BAAI) مؤخرًا برنامج FlagEval Debate، وهو أول منصة مناظرة صينية كبيرة الحجم في العالم. تهدف هذه المنصة الجديدة إلى توفير طريقة قياس جديدة لتقييم قدرة نماذج اللغات الكبيرة من خلال آلية المنافسة الخاصة بمناقشة النماذج. وهو امتداد لخدمة تقييم معركة نموذج المصدر الذكي FlagEval لساحة النماذج الكبيرة، وهدفها هو تحديد اختلافات القدرة بين نماذج اللغات الكبيرة.
هناك بعض المشاكل في معارك النماذج الكبيرة الموجودة، على سبيل المثال، غالبًا ما تكون نتائج معارك النماذج مرتبطة ومن الصعب التمييز بين الاختلافات بين النماذج؛ ويعتمد محتوى الاختبار على تصويت المستخدم ويتطلب مشاركة عدد كبير من المستخدمين الموجودين أساليب المعركة تفتقر إلى التفاعل بين النماذج. ومن أجل حل هذه المشاكل، اعتمد معهد الملكية الفكرية شكل نموذج المناقشة الكبيرة للتقييم.
وباعتبارها نشاطًا فكريًا قائمًا على اللغة، يمكن أن تعكس المناظرة التفكير المنطقي للمشاركين وتنظيم اللغة وتحليل المعلومات وقدرات المعالجة. يمكن للمناقشة النموذجية أن توضح مستوى النماذج الكبيرة في فهم المعلومات، وتكامل المعرفة، والتفكير المنطقي، وتوليد اللغة وقدرات الحوار، مع اختبار عمق معالجة المعلومات والقدرة على التكيف مع الهجرة في سياقات معقدة.
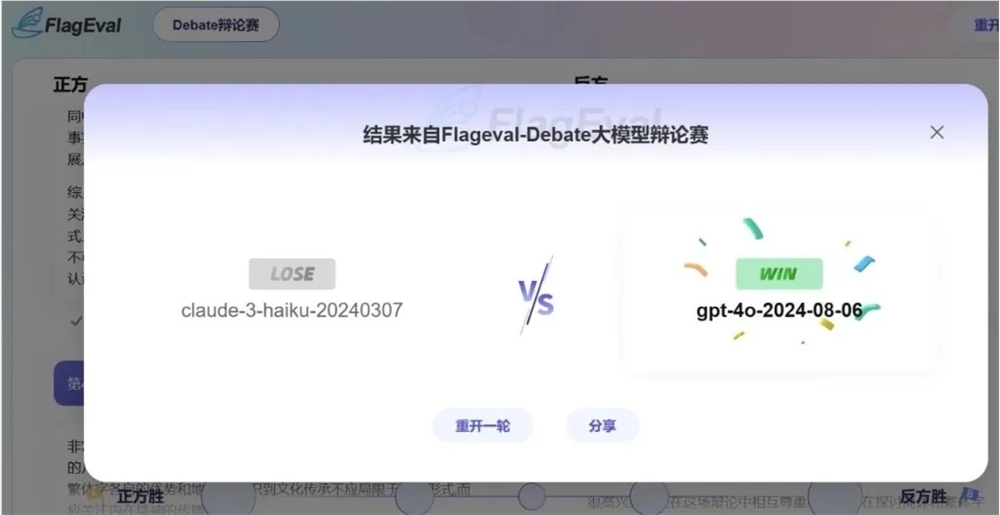
وجد معهد Zhiyuan للأبحاث أن المعارك التفاعلية مثل المناظرات يمكن أن تسلط الضوء على الفجوات بين النماذج وتحسب التصنيفات الفعالة للنماذج بناءً على عدد صغير من عينات البيانات. ولذلك، أطلقوا برنامج FlagEval Debate، وهو منصة مناظرة صينية كبيرة الحجم تعتمد على الاختبار العام.
تدعم المنصة نموذجين لإجراء المناقشات حول مواضيع المناقشة. يتم اختيار موضوعات المناقشة بشكل عشوائي بواسطة المنصة. تتكون قاعدة بيانات موضوعات المناقشة بشكل أساسي من موضوعات البحث الساخنة وخبراء التقييم وموضوعات المناقشة التي تم ترتيبها بواسطة كبار خبراء المناظرة. يمكن لجميع المستخدمين الحكم على كل مناقشة على المنصة لتعزيز تجربة المستخدم.
تتضمن كل مناظرة نموذجية 5 جولات من عرض الآراء، مع إتاحة فرصة واحدة لكل جانب. ومن أجل تجنب الانحراف الناتج عن موضع المربعين الموجب والسالب، سيقوم كلا النموذجين بعمل مربع واحد ومربع سالب واحد لكل منهما. يتنافس كل نموذج كبير في مناظرات متعددة ضد نماذج أخرى، ويتم احتساب الترتيب النهائي للنموذج بناءً على نقاط الفوز.
تتبنى مسابقة المناظرة النموذجية طريقتين: الاختبار العام المفتوح وتقييم الخبراء. وتتكون لجنة التحكيم من لاعبين وحكام من مسابقات المناظرة الاحترافية. يمكن لجمهور الاختبار العام المفتوح التقدير والتصويت بحرية.
صرح معهد Zhiyuan للأبحاث بأنه سيواصل استكشاف المسار الفني والقيمة التطبيقية للمناقشة النموذجية، والالتزام بمبادئ العلم والسلطة والعدالة والانفتاح، والتحسين المستمر لنظام تقييم النماذج الكبيرة FlagEval، وتقديم رؤى وتفكير جديد بيئة التقييم النموذجية الكبيرة
الموقع الرسمي لمناظرة FlagEval:
https://flageval.baai.org/#/debate